While working on parallax mapping, somebody told me about a cool presentation: Sparse virtual textures. The idea is quite simple: reimplement pagination in your shaders, allowing you to have infinite textures while keeping the GPU memory usage constant.
Goal was set: add SVT support to my renderer!
Step 1 - Hand-made pagination
Pagination overview
To understand how SVT works, it is useful to understand what pagination is.
On most computers, data is stored in the RAM. RAM is a linear buffer, and its first byte is at the address 0, and the last at address N.
For some practical reasons, using the real address is not very convenient. Thus some clever folks invented the segmentation, which then evolved into pagination.
The idea is simple: use a virtual address, that is translated by the CPU into the real RAM address (physical). The whole mechanism is well explained by Intel1
This translation possible thanks to pagetables.
Translating every addresses into a new independant one is costly and not needed. That’s why they divided the whole space in pages. A page is a set of N contiguous bytes. For example, on x86, we often talk about 4kB pages.
What the CPU translate are page addresses. Each block is translated as a
contiguous unit. The internal offset remains the same.
This means for N bytes, we only have to store N/page_size translations.
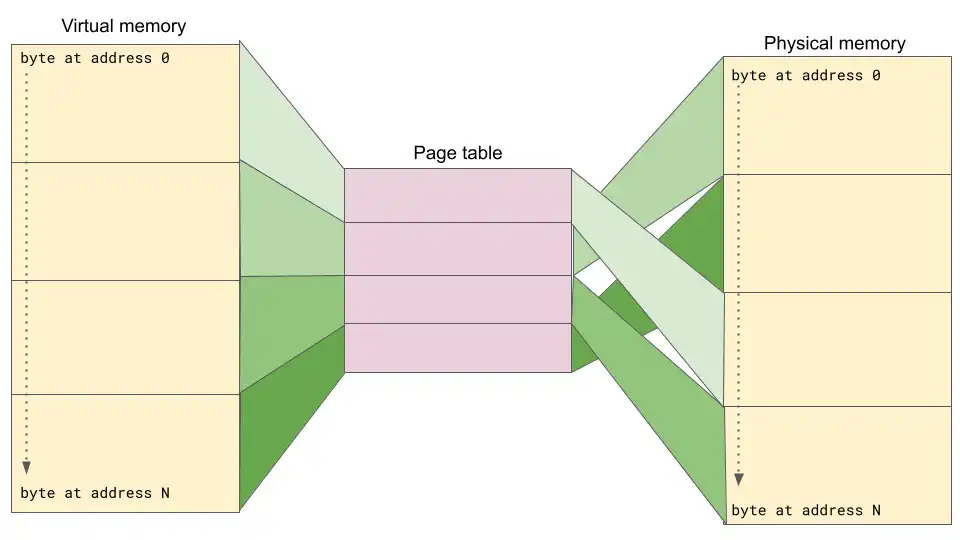
Here on the left you have the virtual memory, divided in 4 blocks (pages). Each block is linearly mapped to an entry in the pagetable.
The mapping can be understood as follows:
- Take your memory address.
- adress = 9416
- Split it into a page-aligned value and the rest.
- 9416 => 8192 + 1224.
- aligned_adress = 8192
- rest = 1224
- Take the aligned value, and divide it by the page size.
- 8192 / 4096 = 2
- index = 2
- This result is the index in the pagetable.
- Read the pagetable entry at this index, this is your new aligned address:
- pagetable[2] = 20480
- Add the rest back to this address:
- physical_address = 20480 + 1224
- You have your physical address.
Adding the page concept to the shader
To implement this technique, I’ll need to:
- find which pages to load
- load them in the “main memory”
- add this pagetable/translation technique.
This could be done using compute shaders and linear buffers, but why not use textures directly? This way I can just add a special rendering pass to compute visibility, and modify my pre-existing forward rendering pass to support pagetables.
First step is to build the pagetable lookup system. This is done in GLSL:
- take the UV coordinates
- split them into page-aligned address, and the rest
- compute page index in both X and Y dimensions
- lookup a texture at the computed index (our pagetable)
- add to the value the rest
 |
|---|
| Showing UV coordinates |
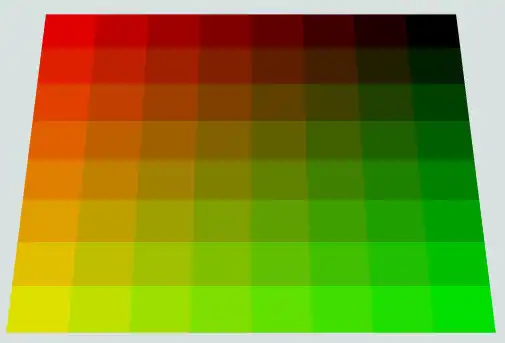 |
|---|
| Showing page-aligned UV coordinates |
Computing visibility
The other advantage of pagination is the ability to load/unload parts of the memory at runtime. Instead of loading the whole file, the kernel only loads the required bits (pages), and only fetch new pages when required.
This is done using a pagefault:
- User tries to access a non-yet loaded address.
- CPU faults, and send a signal to the kernel (page fault).
- The kernel determines if this access is allowed, and loads the page.
- Once loaded, the kernel can resume the user program.
This mechanism requires hardware support: the CPU knows what a pagetable is, and has this interruption system. In GLSL/OpenGL, we don’t have such thing. So what do we do when interrupts don’t exits? We poll!
For us, this means running an initial rendering pass, but instead of rendering the final output with lights and materials, we output the page addresses. (Similar to the illustration image seen above).
This is done by binding a special framebuffer, and doing render-to-texture. Once the pass completed, the output texture can be read, and we can discover which pages are visible.
For this render pass, all materials are replaced with a simple shader:
#version 420 core
/* material definition */
uniform float textureid;
/* Size of a page in pixels. */
uniform float page_size;
/* Size of the pagetable, in pixels (aka how many entries do we have). */
uniform float pagetable_size;
/* Size in pixels of the final texture to load. */
uniform float texture_size;
/* Aspect ratio difference between this pass, and the final pass. */
uniform float svt_to_final_ratio_w; // svt_size / final_size
uniform float svt_to_final_ratio_h; // svt_size / final_size
in vertex_data {
vec2 uv;
} fs_in;
out vec4 result;
/* Determines which mipmap level the texture should be visible at.
* uv: uv coordinates to query.
* texture_size: size in pixels of the texture to display.
*/
float mipmap_level(vec2 uv, float texture_size)
{
vec2 dx = dFdx(uv * texture_size) * svt_to_final_ratio_w;
vec2 dy = dFdy(uv * texture_size) * svt_to_final_ratio_h;
float d = max(dot(dx, dx), dot(dy, dy));
return 0.5f * log2(d);
}
void main()
{
/* how many mipmap level we have for the page-table */
float max_miplevel = log2(texture_size / page_size);
/* what mipmap level do we need */
float mip = floor(mipmap_level(fs_in.uv, texture_size));
/* clamp on the max we can store using the page-table */
mip = clamp(mip, 0.f, max_miplevel);
vec2 requested_pixel = floor(fs_in.uv * texture_size) / exp2(mip);
vec2 requested_page = floor(requested_pixel / page_size);
/* Move values back into a range supported by our framebuffer. */
result.rg = requested_page / 255.f;
result.b = mip / 255.f;
/* I use the alpha channel to mark "dirty" pixels.
* On the CPU side, I first check the alpha value for > 0.5,
* and if yes, consider this a valid page request.
* I could also use it to store a "material" ID and support
* multi-material single-pass SVT. */
result.a = 1.f;
}
Once the page request list retrieved, I can load the textures in the “main memory”.
The main memory is a simple 2D texture, and page allocation is for now simple: first page requested gets the first slot, and so on until memory is full.
 |
|---|
| “Main memory” texture |
Once the page allocated, I need to update the corresponding pagetable entry to point to the correct physical address. This is done by updating the correct pixel in the pagetable:
- R & G channels store the physical address.
- B is unused.
- A marks the entry as valid (loaded) or not.
 |
|---|
| Pagetable texture |
Rendering pass
The final pass is quite similar to a classic pass, except instead of binding one texture for diffuse, I bind 2 textures: the pagetable, and the memory.
- bind the 3D model
- bind the GLSL program
- bind the pagetable and main-memory textures.
At this stage, I can display a texture too big to fit in RAM & VRAM.
Step 2: MipMapping
If you look at the previous video, you’ll notice two issues:
- Red lines showing up near the screen edges.
- Page load increase when zooming out.
First issue is because texture loading doesn’t block the current pass. This means I might request a page, and not have it ready by the time the final pass is ran. I could render it as black, but wanted to make it visible.
The second issue is because I have a 1:1 mapping between the virtual page size and the texture page size. Zooming out to show the entire plane would require loading the entire texture. Texture which doesn’t fit in my RAM.
The solution to both these issues are mipmaps.
- A page at mipmap level 0 covers
page_sizepixels. - A page at mipmap level 1 covers
page_size * 2pixels - …
- A page at mipmap level N covers the whole texture.
Now, I can load the mipmap level N by default, and if the requested page is not available, I just go up in the mip levels until I find a valid page.
Adding mipmaps also allow me to implement a better memory eviction mechanism:
I can now replace 4 pages with one page a level above.
So if I’m low on memory, I can just downgrade some areas, and save 75% of
my memory.
Finally, MipMapping reduces the bandwidth requirements: if the object is far, why load the texture in high resolution? A low-resolution page is enough:
- less disk load.
- less memory usage.
- less latency (since there is less pages to load).
 |
|---|
| Showing physical addresses with MipMapping |
Step 3: Complex materials
The initial rendered had PBR materials. Such material had not only an albedo map, but also normal and roughness+metallic maps. To add new textures, several options:
- New memory textures, new pagetable texture, new pass.
- simple
-
requires an additional pass. This is not OK.
- Same memory texture, same pagetable texture.
- Each page contains in fact the N textures sequentially. So when one page is loaded, N textures are queried and loaded.
-
Easy to implement, but I have to load N textures.
- Same memory texture, multiple pagetable textures.
- pagetables are small, 16x16 or 32x32. Overhead is not huge.
- I can unload some channels for distant objects (normal maps by ex).
- Drawback is I have now N*2 texture sampling in the shader: one for each texture and its associated pagetable.
Because I like the flexibility of this last option, I chose to implement it. In the final version, each object has 4 textures:
- memory (1 mip level)
- albedo pagetable (N mip levels)
- roughness/metallic pagetable (N mip levels)
- normal pagetable (N mip levels)
In the following demo, page loading is done in the main thread, but limited to 1 page per frame, making the loading process very visible.
- Bottom-left graph shows the main memory.
- Other graphs show the pagetables and their corresponding mip-levels.
Page request : subsampling, random and frame budget.
For each frame, I need to do this initial pass to check texture visibility. Reading this framebuffer on the CPU between each frame is quite slow, and for a 4K output, this is prohibitively expensive.
The good news is: I don’t need a 4K framebuffer in that case! Pages are covering N pixels, so we can just reduce the framebuffer size and hope our pages will still be requested!
The demo above is using a 32x32 framebuffer. Which is very small. If done naïvely, this wouldn’t work: some pages would be caught between 2 rendered pixels, and never loaded.
 |
|---|
| 8x8 framebuffer, no jitter. |
A way to solve that is add some jitter to the initial pass. The page request viewpoint is not exactly the camera’s position, but the camera’s position + some random noise.
This way, we can increase coverage without increasing the framebuffer size.
 |
|---|
| 8x8 framebuffer, jitter. |
-
See Intel Architectures Developer’s Manual: Vol. 3A, Chapter 3 ↩